SSIS Logging Part 3
Task Level Logging
Now we are going to start looking at the data that is of interest to the business. Thus far we have looked at an alternative to the built in SSIS logging options. We have a
little more analysis friendly approach, but basically the same kinds of information. What we are talking about next is the detailed data about the business process itself.
There really is not a mechanism built into SSIS to gather this kind of data.
Between the beginning (Initiate Package) and end (Terminate Package) of an ETL process, we have one or more processes that do the actual work of Extracting data from some kind of
source, possibly using some sort of business logic to Transform the data, and finally Loading the data to some predefined destination. We will look at how to capture the
statistics from those operations and put them into a database table from which they can be reported back to the business. We wil also look at handling exceptions that may
occur, both at the individual record level and for the overal ETL task.

The database tables that we will be logging to are the TaskLog, which is of course a child of PackageLog, and the EventLog, which is a child of the TaskLog.
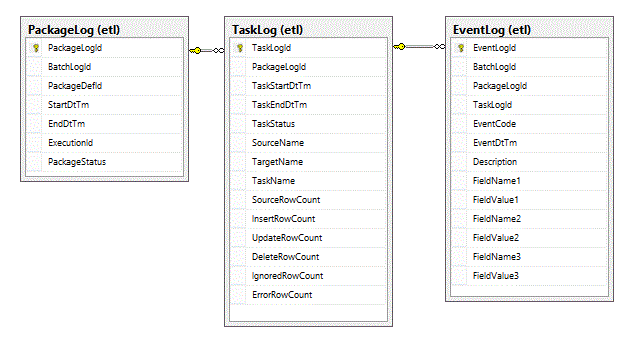
Central to how we do task level logging is the SSIS Sequence Container task.
If you read the previous article, you can probably guess that the Initiate Task and Terminate Task components are going to insert a record into the TaskLog table.
Inside of the DataFlow we will be logging any events of interest to the EventLog table.
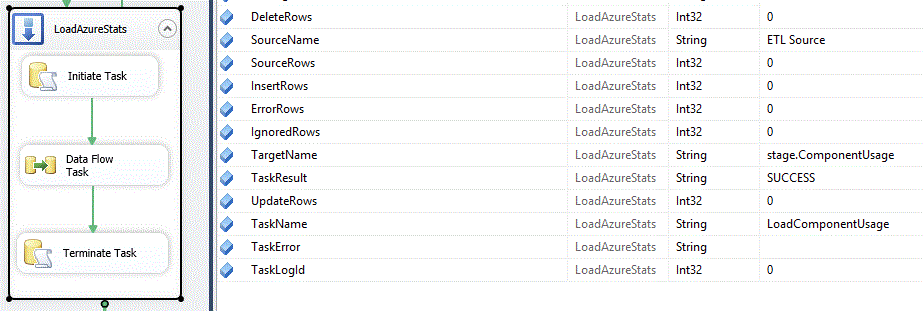
Notice that we have a number of variables defined as the Sequence Container level. Typically, when the Initiate Task component fires you have already determined the Source
and Target for the dataflow. The Task Name will be something that you have set at design time. Many times you will already know the number of rows that will be coming from the
Source. The Initiate Task component calls stored procedure usp_InitiateTask to create the record in the TaskLog table and return TaskLogId to the package.
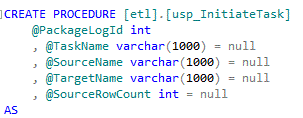
Notice that all the parameters but the first have default values. This is important because you may actually be missing one or more of these pieces of information at the
time the task first starts.
And of course, the Terminate Task component after the data flow will call usp_TerminateBatch, which simply updates the record created earlier.
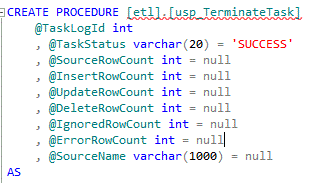
Here also we have default values for all but one of the parameters. Notice also that @SourceRowCount and @SourceName occur in both the Initiate and Terminate stored
procedures. It often happens that you will learn these values as part of the actual processing, so we need to have the flexibility to populate them at either end of
the task.
Now, let's get into the actual workings of TaskLevel logging.
First we'll create a database table and insert a little sample data.
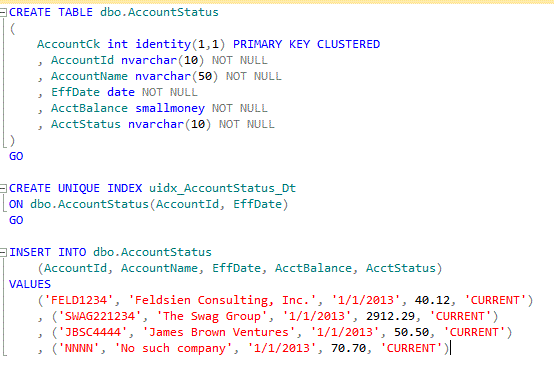
Now, we'll create a pipe delimited flat file, perhaps received from an outside agency, that we will process into our table. We'll intentionally an invalid date as well
as a violation of the uniqe index. We'll put the following rows into a flat file and save it as AcctStatusMonthly.txt.

Let's start getting our package ready by creating a new Flat File Connection which we will call cnAcctStatus. I will assume you know how to do this so I am only going to
say that for purposes of this demo, and actually always a good idea, define the column data types in the flat file exactly the same as the target database table.
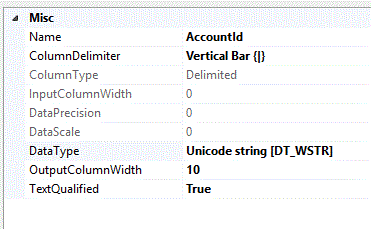
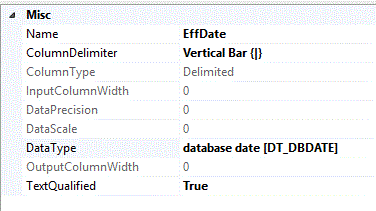 etc.
etc.
For the Sequence Container that contains our task,we need to set the values of some of the variables at design time, and some we will most likely determine with some previous
step in the package. Our TaskName and TargetName will almost always be known at design time. The SourceName and SourceRows may or may not be known before the task executes,
but in this case we are going to hard code them at design time for simplicity's sake.

Now let's look at the details of the DataFlow task.

If you have constructed SSIS packages before, you can see that the "happy path", from the Flat File Source, FFS AcctStatus, to the first OLE DB Destination, Bulk Insert, is
nothing unusual. The main difference here is the manner in which exceptions are handled. First we'll look at the Bulk Insert.
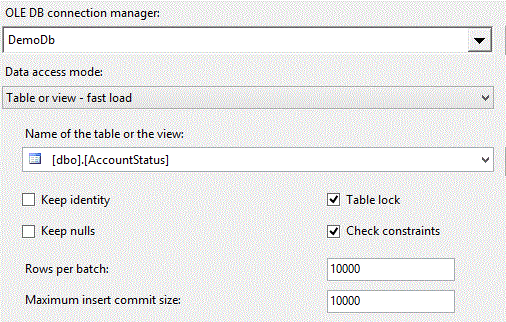
Notice that the "Rows per batch" and "Maximum insert commit size" properties have been changed from their defaults to 10,000. What this means is that rather than the default
behavior of attempting to commit all records received in a single transaction, we are going to process 10,000 records at a time. Be aware that should any one of those 10,000
records fail, the entire batch of 10,000 will be failed.
You may be aware that the default behavior when a row fails is that the entire component fails. Here again we are changing from the default and instructing SSIS to
redirect any failing batches.

Getting back to the source file that we created earlier, remember that we deliberately created one record that will fail on the unique index. Since there were only a few
records in the file, the entire batch will fail and be redirected.
The batch of records that failed in Bulk Insert will now be picked up by the Row by Row Insert component. As you may guess, this component will process records one row at
a time. We do this simply by setting the "Data access mode" property to "Table or view".
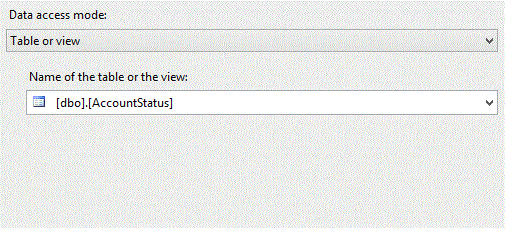
And again, we are overriding the default and telling SSIS to redirect any failing rows.
So, when this runs, all records will fail the Bulk Insert component, but only ONE record will fail Row by Row. The good records get processed.
Our failing records will be processed by the script component "Table Err Handler". Again, I will assume you have a little familiarity with script components. Here are the Inputs
and outputs for the component.

In addition to the columns coming from the data source, we have two new columns, ErrorCode and ErrorColumn comming from the "Row by Row Insert" component. Below that, we have
defined several new columns which will be added to the incoming rows. These columns are the same names and data types as our EventLog table.
As each failing row reaches the script component, it fires the Input0_ProcessInputRow event. We override that event to produce a record to go into the EventLog table. Our
objective here is to positively identify the row that failed and get a good description of the error that occurred. We also want to keep track of the number of ErrorRows
that we process and we will adjust the count of InsertRows accordingly in the PostExecute event.
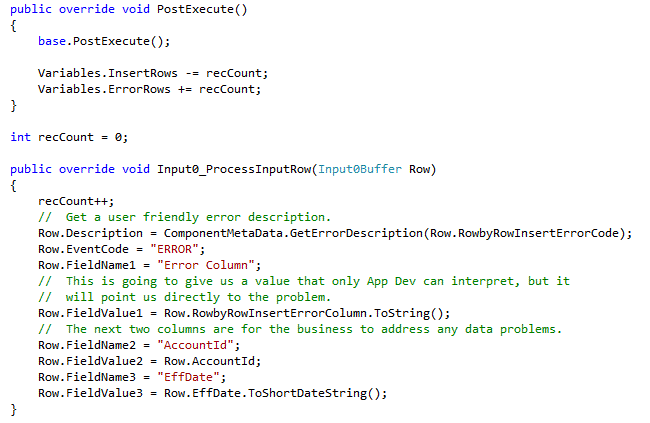
The output from the script component then maps to an OLE DB Destination pointing to our EventLog table.
Handling errors that occur in the file is a pretty similar operation. First we set the flat file source to redirect errors.
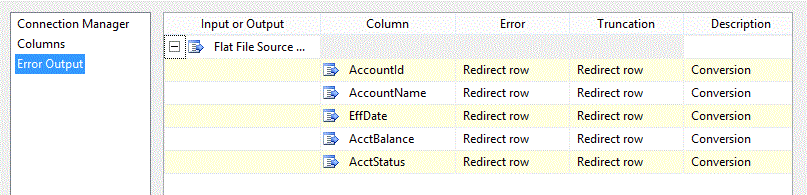
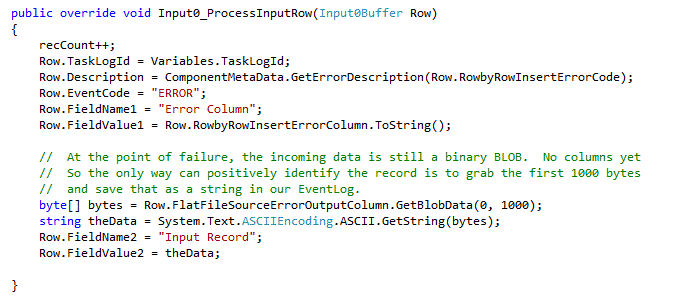
The script in the File Err Handler script component is nearly identical to the Table Err Handler. There is just a slight difference in the way that the failing row is
logged. Here is our script.
That's all there is to it. We now have everything we want to know about an ETL package in a few tables that can easily be put into report form.
